블루투스 음성인식 활성화/비활성화에 대한 스펙 문서은 아래 링크에서 다운 받을 수 있습니다.
아래 두개의 그림은 블루트스 프로파일 스트럭쳐와 프로파일의 종속 관계를 설명하고 있는데,
첫번째 그림은 1.5 스펙에 있는 그림이고, 두번째 그림은 1.6 스펙에 있는 그림입니다. 복잡하네요... ㅠㅠ
 [1.5 스펙 Bluetooth profiles 그림]
[1.5 스펙 Bluetooth profiles 그림]
 [1.6 스펙 Bluetooth profiles 그림]
[1.6 스펙 Bluetooth profiles 그림]
아래 글은 en.wikipedia.org에 Hands-Free Profile (HFP) 관련 설명 중 일부입니다.
1.6 버전에는 mSBC codec을 사용한 wide band speech (16Khz 모노 음성)가 옵션 사항으로 추가되었다고 하는 군요.
이것은, 기존에 BT 음성인식은 8Khz 모노만 지원되었었는데,
1.6 버전에서는 BT 음성인식에서 16Khz 모노가 Optional로 지원 가능하도록 하였다는 의미겠군요...
Currently in version 1.6, this is commonly used to allow car hands-free kits to communicate with mobile phones in the car. It commonly uses Synchronous Connection Oriented link (SCO) to carry a monaural audio channel with continuously variable slope delta modulation or pulse-code modulation, and with logarithmic a-law or μ-law quantization. Version 1.6 adds optional support for wide band speech with the mSBC codec, a 16 kHz monaural configuration of the SBC codec mandated by the A2DP profile.
(출처: https://en.wikipedia.org/wiki/List_of_Bluetooth_profiles)
스펙 내용중에서...
음성인식 활성화와 비활성화 (Voice Recognition Activation/Deactivation)에 대한 내용만 간단하게 살펴보자면...
우선, Audio Gate (AG)와 Hands-Free unit (HF)에 정의에 대해서 기술되어 있습니다.
AG는 일반적으로 핸드폰이고, HF는 BT 디바이스나 HF가 설치된 차량에 해당합니다.
 [핸즈프리의 전형적인 예]
[핸즈프리의 전형적인 예]
The following roles are defined for this profile:
Audio Gateway(AG) – This is the device that is the gateway of the audio, both for input and output. Typical devicesacting as Audio Gateways are cellular phones.
Hands-Free unit (HF) – This is the device acting as the Audio Gateway’s remote audio input and output mechanism. It also providessome remote control means.
블루투스 관련 AT 커멘드는 여러가지가 있지만,
그 중에서, 음성인식 활성화/비활성화 관련 커멘드는 "AT+BVRA=0", "AT+BVRA=1" 등이 있고,
결과 코드로 "+BVRA:0", "+BVRA:1" 등이 있습니다.
4.33.3 Bluetooth Defined AT Capabilities
The new Bluetooth specific AT capabilities are listed below:
AT+BVRA (Bluetooth Voice Recognition Activation)
Syntax: AT+BVRA=<vrec>
Description:
Enables/disables the voice recognition function in the AG.
Only support for execution command is mandated. Neither the read nor test commands are mandatory.
Values:
<vrec>: 0, 1, entered asinteger values, where
0 = Disable Voice recognition in the AG, 1 = Enable Voice recognition in the AG
+BVRA (Bluetooth Voice Recognition Activation)
Syntax: +BVRA: <vrect>
Description:
Unsolicited result code used to notify the HF when the voice recognition function in the AG is activated/deactivated autonomously from the AG.
The unsolicited +BVRA:1 result code shall not be sent by the AG to the HF if the corresponding voice recognition activation has been initiated by the HF. Likewise, the unsolicited +BVRA:0 result code shall not be sent by the
AG to the HF if the corresponding voice recognition deactivation has been initiated by the HF, regardless of which side initiated the voice recognition activation.
Values:
<vrect>: 0, entered as integer value, where
0 = Voice recognition is disabled in the AG, 1 = Voice recognition is enabled in the AG
음성인식 활성화는,
첫번째, HF(BT 디바이스) 쪽에서 AT+BVRA 명령어를 사용해서 활성화 또는 비활성화를 하는 경우가 있고,
둘번째, AG (핸드폰) 쪽에서 자체적으로 활성화 또는 비활성화를 하는 경우도 있습니다.
AG가 음성인식을 지원하는 경우에는, AT+BVRA 명령어를 지원해야 합니다.
첫번째의 경우, HF에서 AT+BVRA 명령어를 던지면,
AG는 OK 결과 코드로 응답을 하고,
오디오 커넥션이 이미 설정되어 있지 않다면 셋업을 진행하고 음성 입력을 시작해야 합니다.
만약에, AG가 음성인식을 지원하지 않는 경우에는, AG는 에러를 알려 주어야만 합니다.
두번째의 경우, AG에서 음성인식을 활성화하는 경우에는, +BVRA: 1 결과 코드를 HF에 전달하여야만 합니다.
그리고, 오디오 커넥션이 이미 설정되어 있지 않다면 셋업을 진행하고 음성 입력을 시작해야 합니다.
4.25 Voice Recognition Activation
The HF, via the AT+BVRA command, or the AG autonomously, may activate/deactivate
the voice recognition function resident in the AG. Beyond the audio routing and voice
recognition activation capabilities, the rest of the voice recognition functionality is
implementation dependent.
Whenever the AG supports a voice recognition function it shall support the AT+BVRA
command as described in the procedures in this section.
If the HF issues the AT+BVRA command, the AG shall respond with the OK result code
if it supports voice recognition, then initiate an Audio Connection to the HF (if the Audio
Connection does not already exist) and begin the voice input sequence.
If the AG does not support voice recognition, the AG shall respond with the ERROR
indication.
When the voice recognition function is activated from the AG, it shall inform the HF via
the +BVRA: 1 unsolicited result code and the AG shall initiate an Audio Connection to
the HF (if the Audio Connection does not already exist) and begin the voice input
sequence.
 [핸즈프리로부터 음성인식 활성화]
[핸즈프리로부터 음성인식 활성화]
 [오디오게이트로부터 음성인식 활성화]
[오디오게이트로부터 음성인식 활성화]
일단 활성화가 되면, AG는 음성인식 활성화 상태를 유지해야만 합니다.
AG쪽에서 음성인식을 비활성화 하는 경우에는 +BVRA: 0 결과 코드를 HF쪽으로 전달해야 합니다.
HF쪽에서 음성이식을 비활성화 하는 경우에는 AT+BVRA 명령을 던집니다.
그리고, 여러가지 이유로 AG와 HF 사이의 커넥션이 끊어지는 경우가 있을 수 있습니다.
Once activated, depending upon the voice recognition implementation, the AG shall then keep the voice recognition function enabled:
• For the duration of time supported by the implementation (“momentary on” voice recognition implementation). In this case, the AG shall notify the HF by sending a +BVRA: 0 unsolicited result code.
• Or until the AT+BVRA command is issued to disable voice recognition from the HF.
• Or until the current Service Level Connection between the AG and the HF is dropped for any reason.
 [오디오게이트로부터 음성인식 활성화]
[오디오게이트로부터 음성인식 활성화]
 [핸즈프리로부터 음성인식 활성화]
[핸즈프리로부터 음성인식 활성화]
관련 약어들 모음입니다.
< List of Acronyms and Abbreviations >













 16KHz_Sweep.zip
16KHz_Sweep.zip









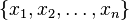 , the RMS
, the RMS
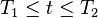 is
is![f_{\mathrm{rms}} = \sqrt {{1 \over {T_2-T_1}} {\int_{T_1}^{T_2} {[f(t)]}^2\, dt}},](http://upload.wikimedia.org/math/1/8/d/18d7849093bc289403a534d37cd20838.png)
![f_\mathrm{rms} = \lim_{T\rightarrow \infty} \sqrt {{1 \over {T}} {\int_{0}^{T} {[f(t)]}^2\, dt}}.](http://upload.wikimedia.org/math/0/3/8/03818626990ed332916202cfaa40400c.png)
